📚해당 게시글은 '이지스 퍼블리싱' 출판, 데이터 분석가 '김영우'님이 지은 도서 "Do it! 쉽게 배우는 R 데이터 분석" 을 기반으로 작성된 게시글입니다. 저작권 문제 시 게시글을 삭제 하겠습니다 :)
어제까지는 정말정말 기본적인 함수들에 대해서 공부했다면, 오늘은 약간 조금 레벨업 된..? (아직까지 기본이지만..)
오늘 하면서 느낀건데, 할수록 뭔가 재미있는거 같다ㅋㅋㅋ 아직 쉬우니까 그러겠지..
- 데이터 프레임
데이터 프레임은 쉽게 말해서 "표"이다. 열(세로)은 컬럼, 변수라고도 불리며, 속성을 나타낸다.
행(가로)은 row, 케이스라고 불리며, 각 사람/사물(?)에 대한 정보를 보여준다.
"데이터가 크다"는 말은 행이 많거나, 열이 많은 것을 의미한다.
그럼 이제 R을 이용해 데이터 프레임을 만들어보자! 교재따라서 시험 성적 데이터를 만들어볼거다.
| 이름 | 영어 | 수학 |
| 홍길동 | 90 | 50 |
| 이순신 | 80 | 60 |
| 김철수 | 60 | 100 |
| 김미영 | 70 | 20 |
위의 표를 고대로 R에 입력해 보았다.

여기서 팁은, 데이터 프레임 이름을 정할때는 Data Frame의 약자 df를 붙여주면, 다른 변수들과 구분하기 쉽다는 것.
그래서 나도 df_midterm이라고 변수 이름을 정했다.
이후, 어제 배운 mean()함수를 이용해 점수의 평균을 산출했다.
코딩 속에 보이는 $기호는 데이터 프레임 안에 있는 변수를 지정할 때 사용한다.
ex. df_midterm$math : df_midterm이라는 데이터 프레임 내에 math라는 변수
추가로, 위의 과정에서는 변수를 하나씩 지정해주고 마지막에 데이터 프레임을 생성했다.
이번에는 쉼표(,)를 이용해 한번에 변수를 지정해 데이터 프레임을 생성했다.
중간중간 줄바꿈은 코드가 길어질 때, 알아보기 쉽게 하기 위해 다음 줄로 넘겨 준 것.
그러면 앞에 프롬프트 시작이 ">"이 아니라 "+"가 된다. 아직 앞의 코드가 끝나지 않았다는 뜻!

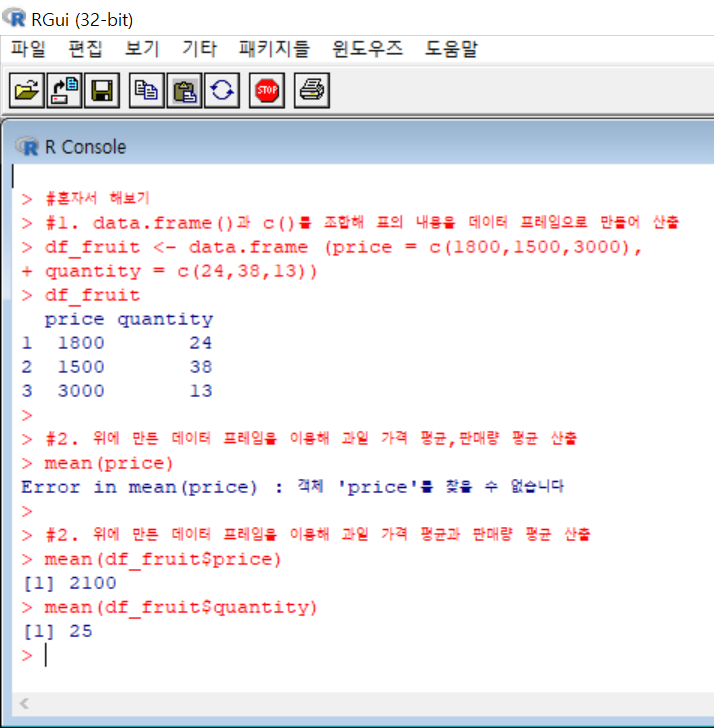
앞에 했던 것들을 그대로 응용해 문제를 풀어봤다.
책보면서 따라할땐 '뭐야 쉽네?!"했었는데, 고새 문제풀때 mean(price)라고 코딩하고 있다... 오류떴을때 잠깐 띠용함..
그래도 이렇게 중간중간 틀리는게 있어야 인간미 있지...?하핳
SPSS였으면 어디서 틀렸는지도 모르고 실행취소하고 욕하면서 처음부터 다시했을꺼야..ㅋㅋ
- 외부 데이터 불러오기(엑셀)
이제는 내가 직접 데이터를 입력하는게 아닌, 외부의 데이터를 이용하는 과정이다. (책의 실습 파일이 깃허브에 공유되어 있어서 좋다.)
R로 불러오기 전에, 엑셀 파일을 불러오는 기능을 제공하는 패키지("readxl")를 설치하고 로드했다.그리고, read_excel() 함수를 이용해 엑셀 파일을 불러왔다.그리고 불러온 엑셀 데이터를 기반으로 mean()함수를 이용해 분석해보았다.
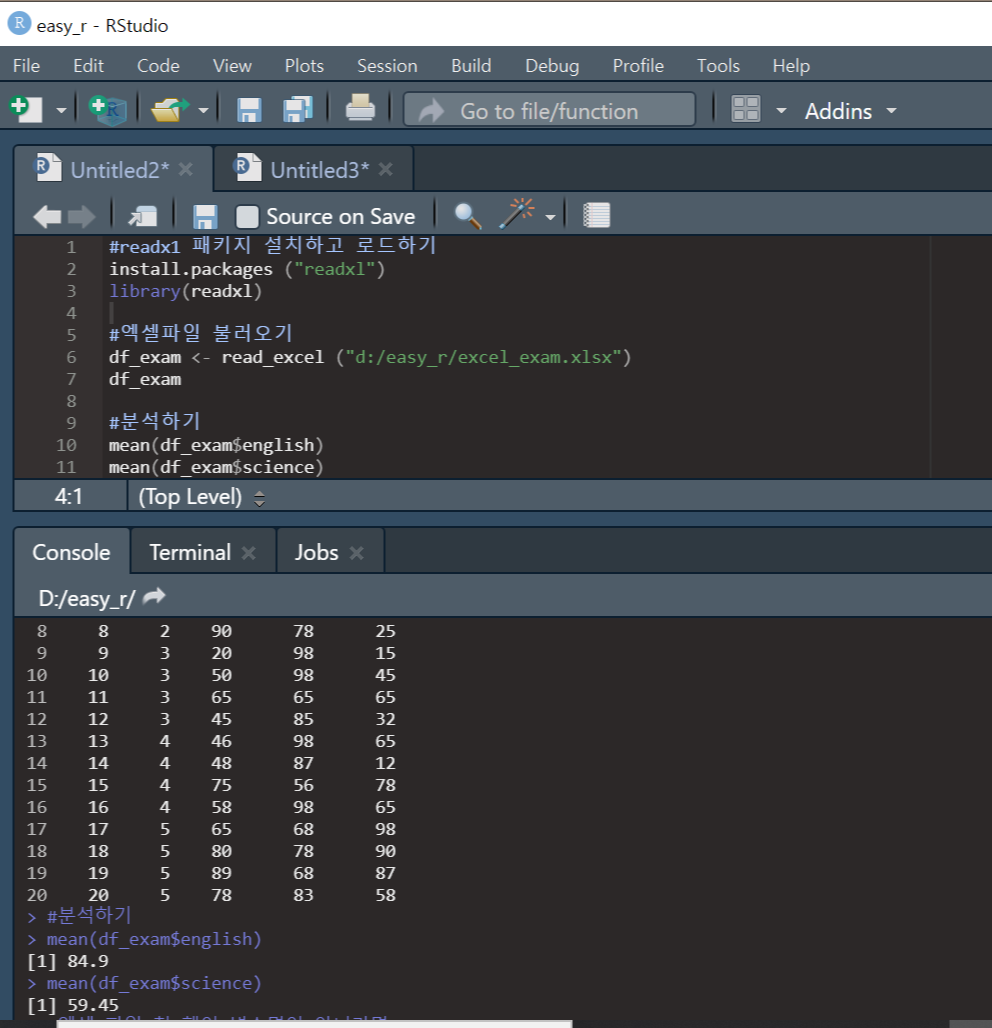
read_excel()함수를 이용할 때, 괄호 안에는 확장자(.xlsx)를 포함한 파일명을 모두 적어야 하고, 앞뒤로 따옴표(")를 꼭 넣어야 한다!!
만약, 파일이 프로젝트 폴더가 아닌 다른 폴더에 있는 경우, 슬래시(/)를 이용해 경로를 직접 지정해줘야 한다.
나는 따로 폴더를 만들어 사용하는지라 따로 지정해줬다.
만약 엑셀 파일 첫번째 행이 변수명이 아니라면?

변수명 없이 바로 데이터부터 시작하는 파일인 경우,
read_excel() 함수 안에 "col_names = F"파라미터를 설정해주면 된다. F는 False(거짓)을 의미하며, '열 이름을 가져올것인가?'라는 질문에 '아니오'라고 대답한 셈이다. 이와 같은 논리형 벡터를 입력할때는 TRUE, FALSE, T, F등 대문자로 입력해야한다.
만약 시트가 여러개인 엑셀 파일이라면?

read_excel() 함수 안에 "sheet = "이라는 파라미터를 이용하면 된다, 'sheet = 3'이라고 입력하면 엑셀 파일의 시트3을 불러온다는 뜻이다.
- 외부 데이터 불러오기(CSV 파일)
CSV 실습 파일도 깃허브에서 받아왔다. CSV 파일 불러오기도 아까 설치한 "readxl" 패키지로 실행 가능하다.
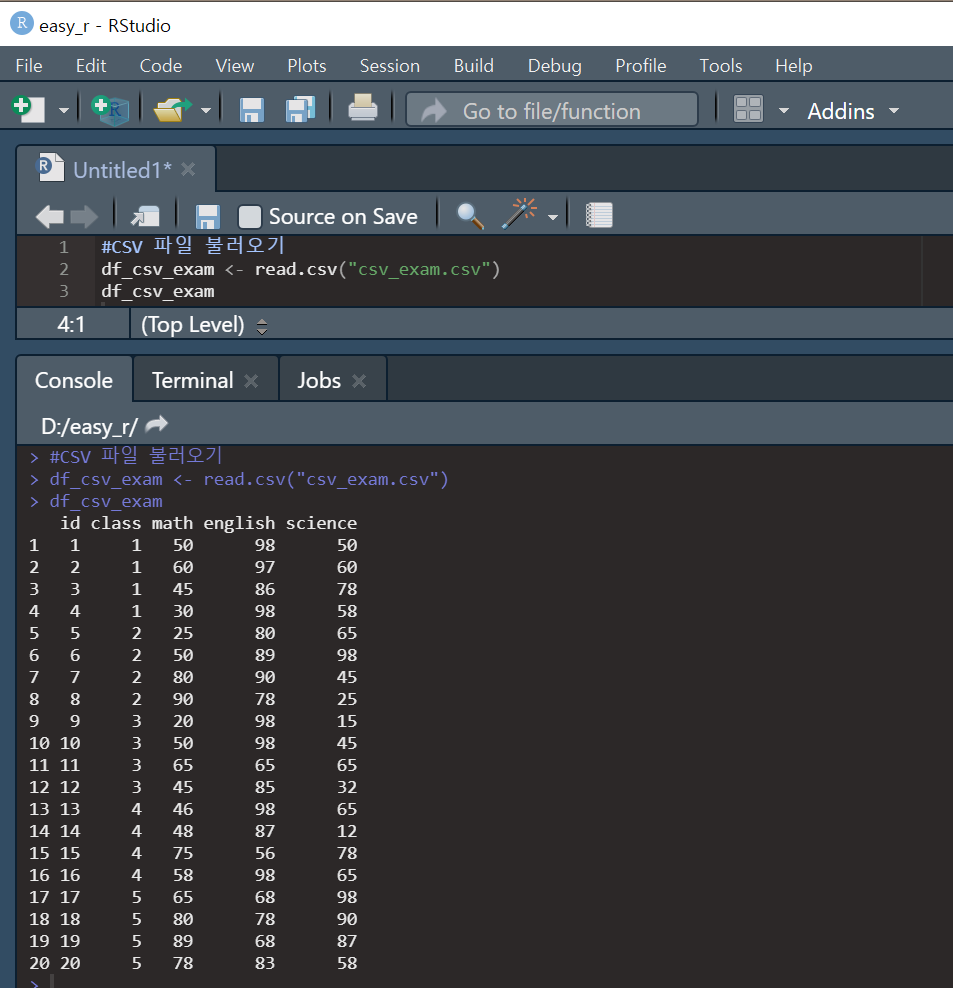
read.csv() 함수를 이용해 csv 파일을 불러왔다. 괄호 안에 들어올 파일명은 위에 엑셀 파일과 같이 확장자까지 입력하고, 앞뒤로 따옴표를 붙여주면 된다.
대신, read_excel()의 col_names = F와 기능은 같지만 파라미터 이름이 달라져, CSV 파일에서는 "header= F"를 사용한다.
참고로, 실습에 사용한 CSV 파일은 보다시피 모두 숫자로 구성되어있다. 하지만 만약 CSV 파일에 문자가 들어있는 경우,
stringsAsFactors = F 를 사용해줘야 한다. ex. read.csv("csv_exam.csv", stringsAsFactors = F)
그럼 내가 만약 R에서 데이터 프레임을 작성하고 그거를 CSV 파일로 저장하려면?
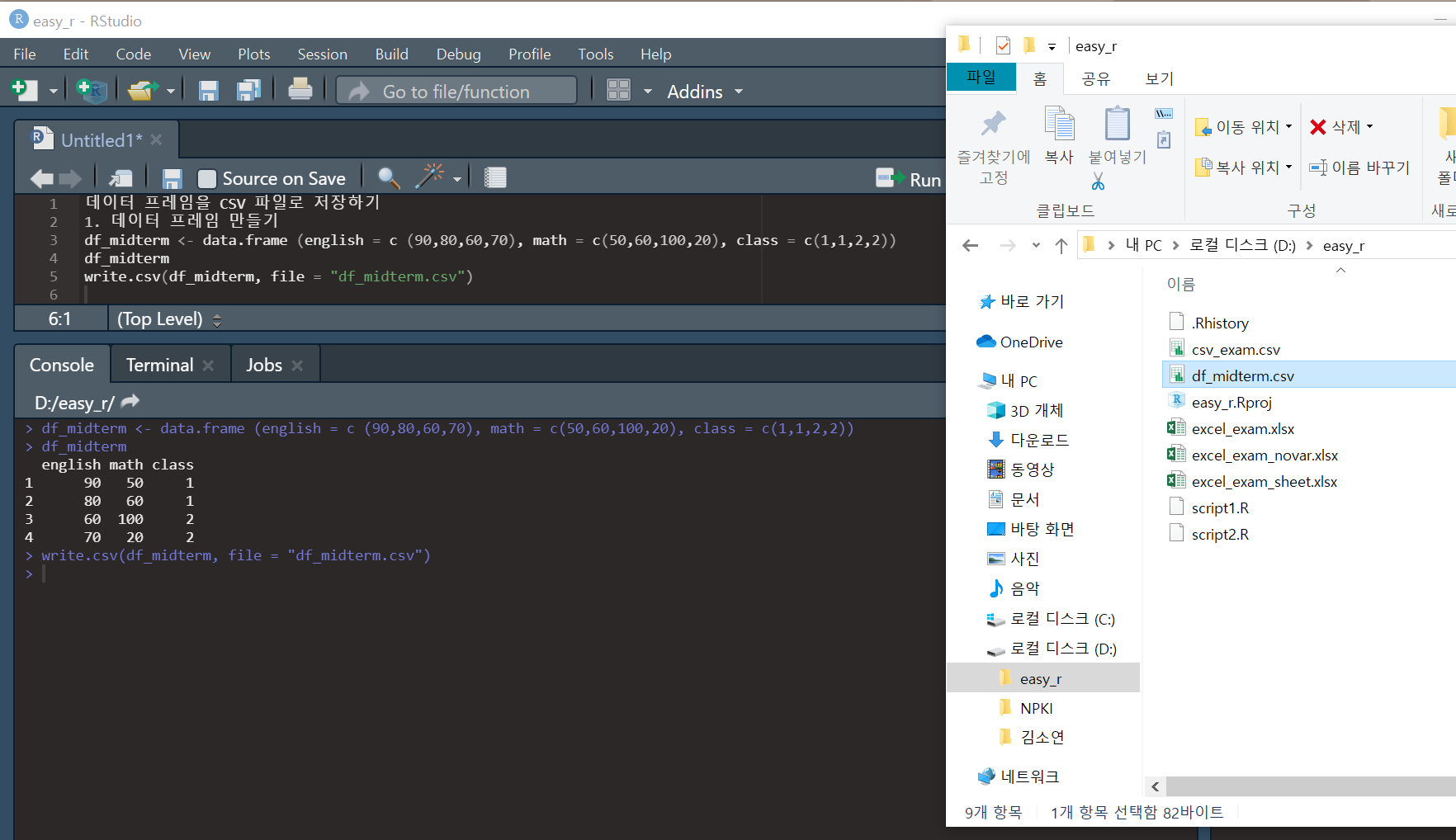
Data frame을 만들어 주고, write.csv()함수를 이용해 데이터 프레임을 csv 파일로 저장했다. 괄호 안에는 저장할 데이터 프레임명과, file 파라미터에 파일 명을 지정해주면 된다. 파일명은 앞뒤로 따옴표(")를 붙여줘야 한다.
-RDS 파일 활용하기
RDS 파일은 R 전용 데이터 파일이다. 다른 파일들에 비해 R에서 RDS 파일을 읽으면 속도가 빠르고 용량이 작다는 장점이 있다.
대신, R을 사용하지 않는 사람과 파일을 주고받을때는 CSV파일로 저장해서 공유해야한다.

RDS 파일로 저장할 때는 saveRDS() 함수를 사용해주면 되고, 괄호 안의 규칙은 CSV 파일을 저장할 때와 같다.
반대로, RDS 파일을 불러올때는 readRDS() 함수를 사용하며, 괄호 안은 지금까지 했던 것과 같은 형태로, 확장자를 포함한 전체 파일 명을 따옴표와 함께 적어주면 된다. (대신, 프로젝트 폴더 외부에 있을때는 슬래쉬(/)를 이용해 경로 지정해줄 것!)
이렇게 4강에서는 변수를 지정해 데이터프레임 만들기, 그리고 엑셀, CSV, RDS 등 외부 데이터를 저장하고 불러오는 방법들에 대해 알아봤다. 아직까지는 재밌기도 하고 쉬운거 같아서 힘들진 않지만, 이런 저런 함수를 이용하면서 '왜.. 도대체 왜.. 함수명은 똑같이 안해놓는걸까.. 왜... 파일마다 함수가 다르게 해놨을까.."생각했다..ㅋㅋㅋㅋㅋ 어떤건 write.csv() 어떤건 saveRDS().. 어떤건 언더바(_), 어떤건 마침표(.),,,ㅋㅋㅋ 그냥 다 통일해달란 말이다!!는 나의 그냥 작은 불만?이겠지.. 하다보면 다 머리에 박혀있겠지 뭐...
다음 게시글은 5강이다!
'(통계분석) R' 카테고리의 다른 글
| 09.25(금) 데이터 전처리, 필요한 데이터 추출, 필요한 변수 추출 (0) | 2020.09.28 |
|---|---|
| 09.24(목) 데이터 파악, 변수명 변경, 파생변수 생성 (0) | 2020.09.27 |
| 09.23(수) 변수, 함수, 패키지 이해하기 (0) | 2020.09.26 |
| 09.23(수) R의 기본 개념, R 사용의 장점 (0) | 2020.09.26 |
| 09.22(화) R과의 첫..만남.. (0) | 2020.09.26 |