📚해당 게시글은 '이지스 퍼블리싱' 출판, 데이터 분석가 '김영우'님이 지은 도서 "Do it! 쉽게 배우는 R 데이터 분석" 을 기반으로 작성된 게시글입니다. 저작권 문제 시 게시글을 삭제 하겠습니다 :)
-순서대로 데이터 정렬하기
arrange(): 데이터를 오름차순으로 정렬
arrange(desc()): 데이터를 내림차순으로 정렬
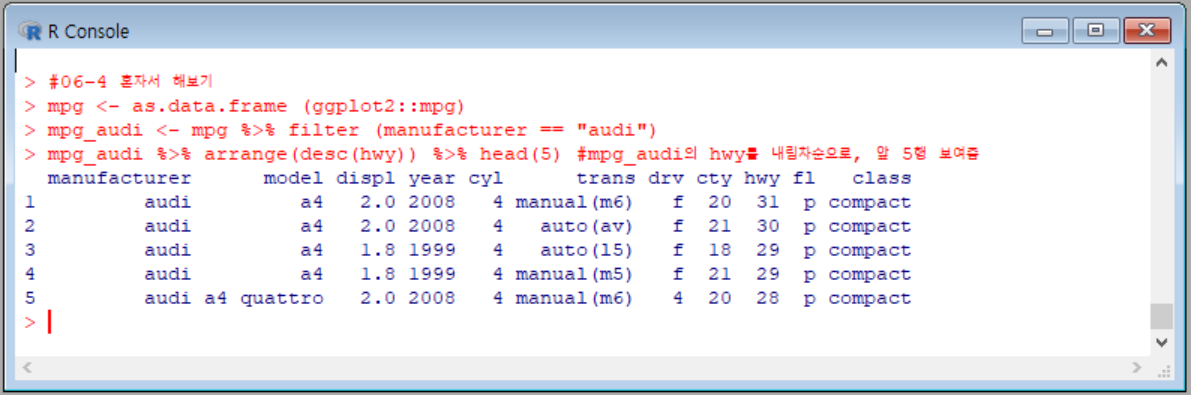
오름차순, 내림차순으로 데이터를 정렬하는 함수는 매우 간단하다.
위의 문제에서는 filter()함수, arrange() 혹은 arrange(desc())함수, head()함수를 조합해 1~5위에 해당하는 자동차의 데이터를 출력했다. 이와 같이 여러가지 함수를 %>%로 연결해 나열하면 다양한 결과값을 얻을 수 있다.
- 파생변수 추가하기
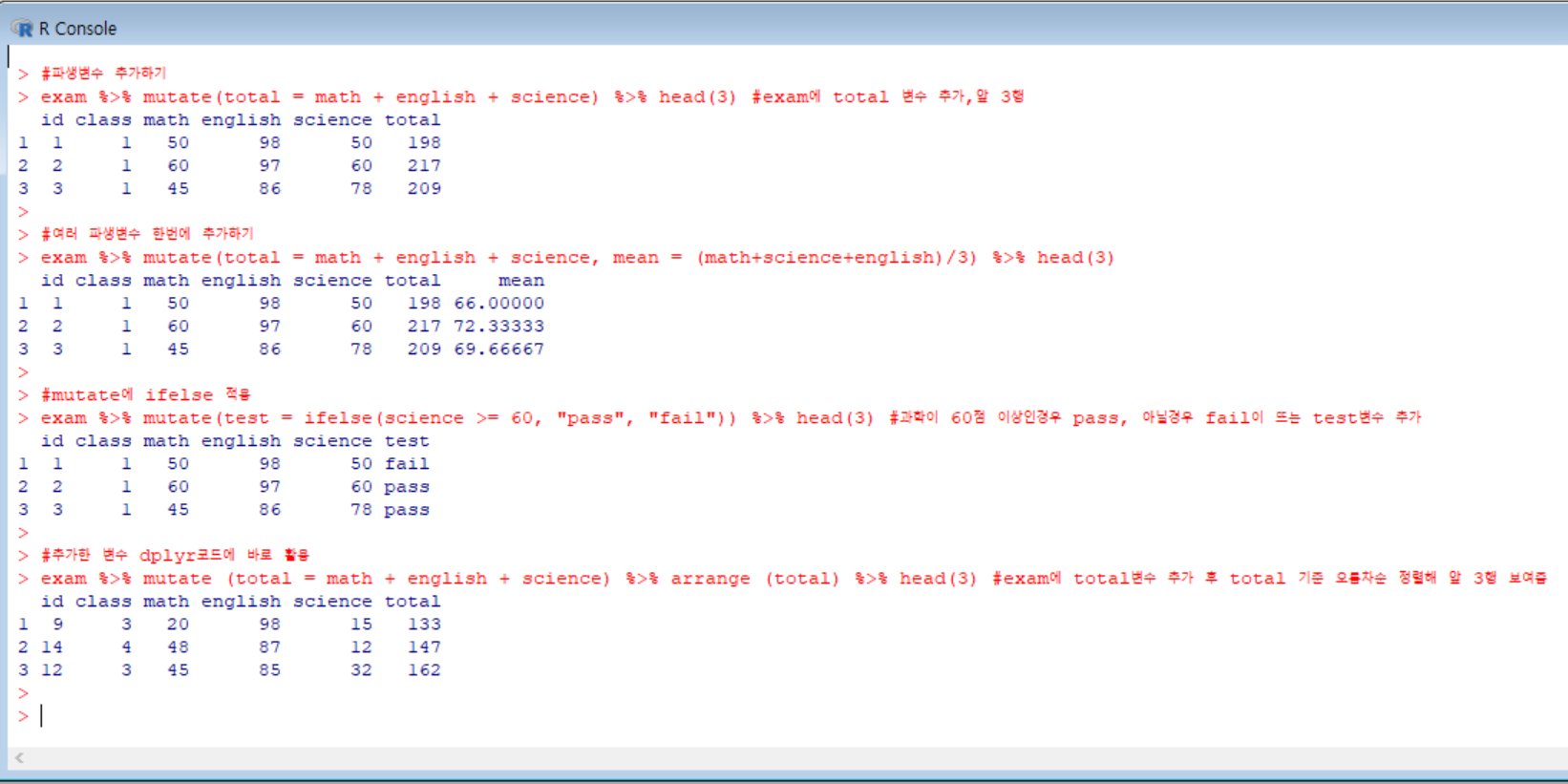
파생변수를 추가할 때는 mutate() 함수를 활용한다. dplyr 함수를 사용하기 전에는,
var3 <- var1 + var2 이런 식으로 <- 기호를 이용해 파생변수를 추가했지만, dplyr 함수를 이용하면 코드가 훨씬 간단해진다는 장점이 있다.
mutate() 함수는 dplyr패키지의 함수로, 파생변수를 추가할 때 사용한다. 괄호 안에 콤마(,)를 이용해 여러가지 변수를 새로 만들 수 있다.
또한, mutate()함수 내에 ifelse()함수를 이용할 수도있는데, 예를 들어 '수학이 60점 이상인 경우에는 pass가, 미만인 경우에는 fail이 나오도록' 변수를 생성할 수 있다.
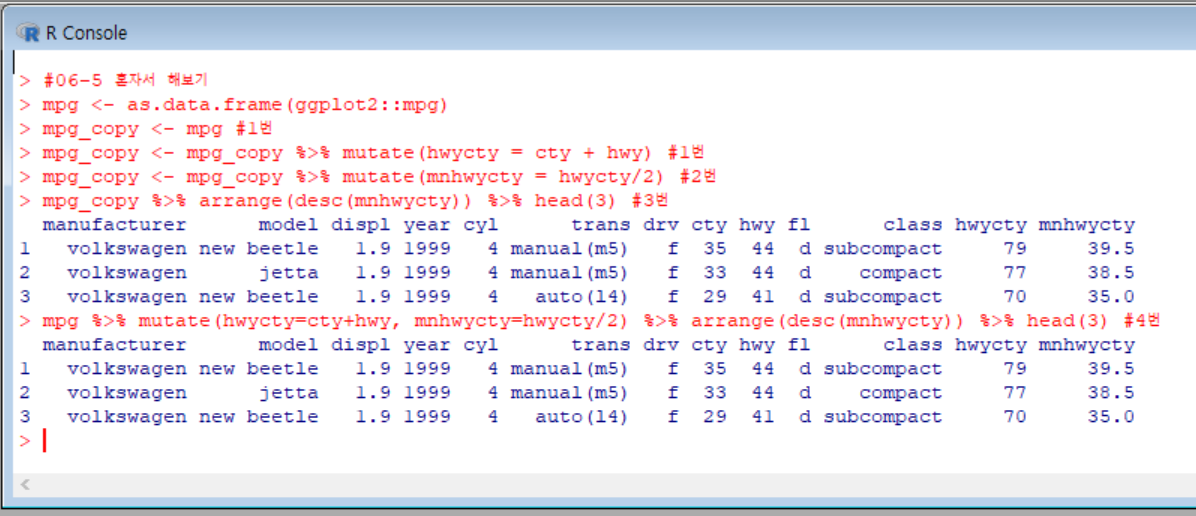
우선, ggplot2 패키지의 mpg 데이터를 데이터프레임 형식을 불러왔다.
mpg 데이터는 추후 실습에도 계속 사용 할 수 있도록 mpg_copy에 복사해뒀고, 이번 문제의 실습은 mpg_copy 데이터를 이용했다.
#1. mpg_copy에서 hwy와 cty 값을 더한 hwycty 변수 생성
#2. mpg_copy에서 1번에서 구한 hwycty의 평균인 mnhwycty 변수 생성
#3. mpg_copy에서 mnhwycty변수가 높은 순서대로 자동차 3종의 데이터 출력
#4. 1~3의 문제를 한번에 출력할 수 있는 dplyr 구문 생성 (이런 문제의 경우, 1~3에서 사용한 함수들을 모두 %>%로 연결해주면 된다!)
- 집단별로 요약하기
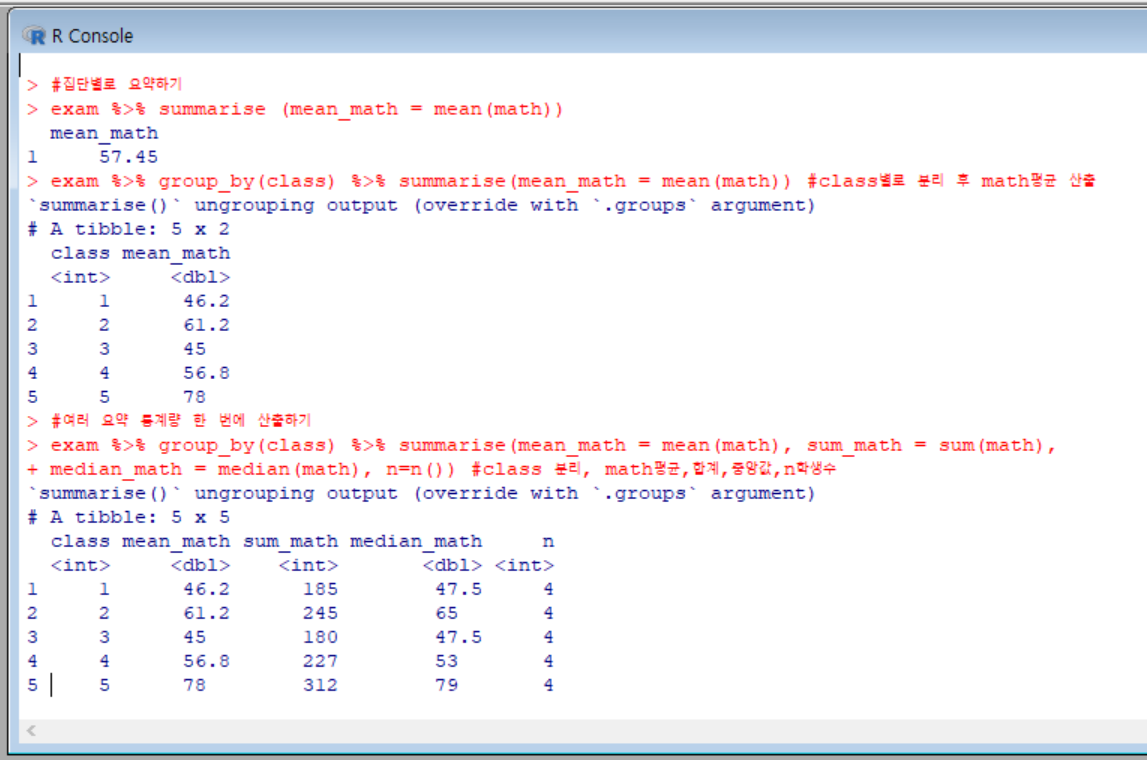
전체의 평균을 구한다면 간단히 mean()을 사용하면 된다.
summarise()는 group_by()와 조합해 집단별 요약표를 만들 때 사용한다.
n() 함수는 데이터가 몇행으로 되어있는지 빈도를 구하는 기능을 한다.
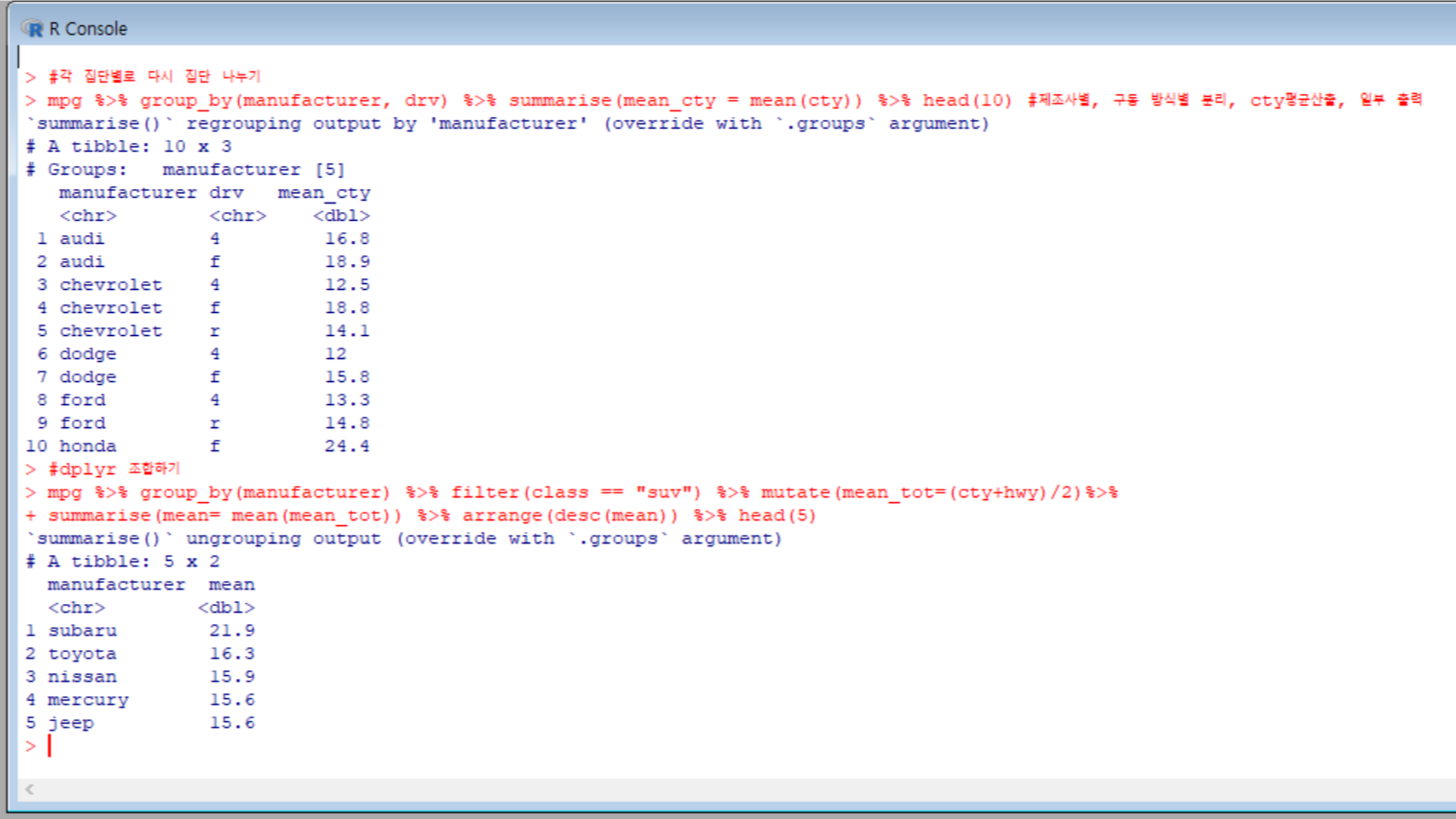
이번에는 summarise(), group_by()함수, 다른 다양한 함수들을 조합해 dplyr 구문을 만들었다.
회사별로 분리하고, suv를 추출해서, 통합 연비 변수를 생성하고, 통합 연비 평균을 산출해 내림차순으로 정렬해 1~5위까지 출력하는 과정이다.
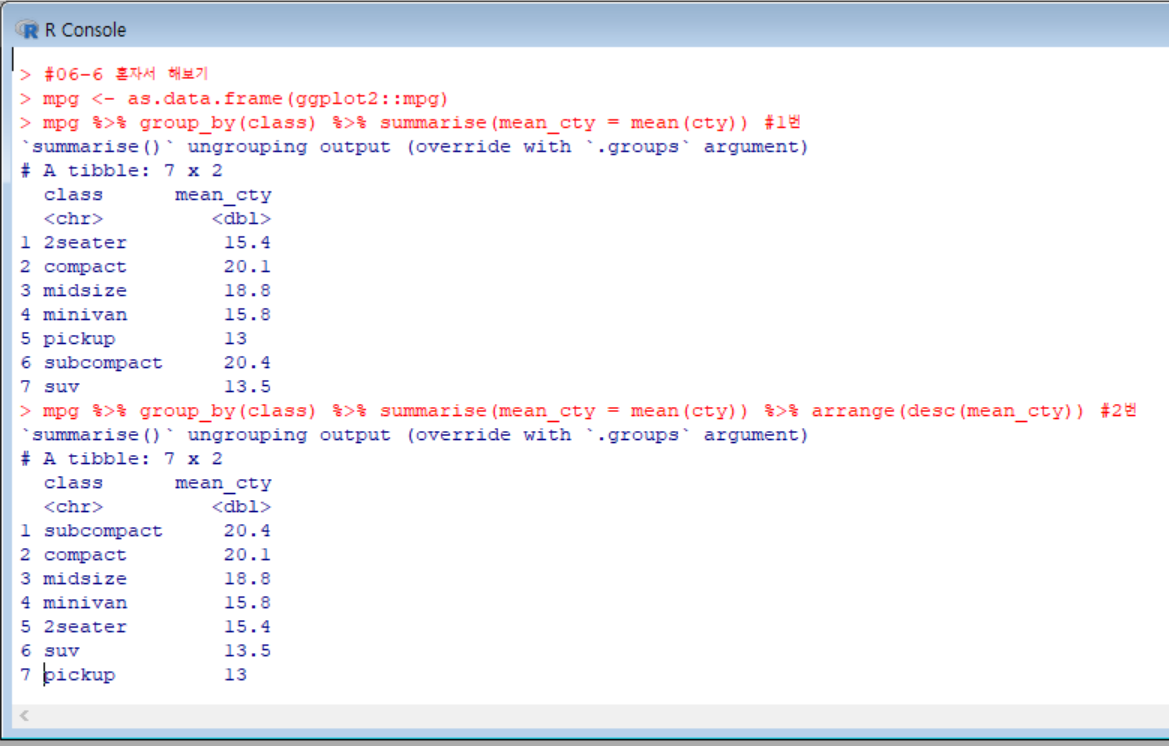
1번은 mpg 데이터에서 class 별 cty 평균을 구하는 과정.
2번은 mpg 데이터에서 class별 cty 평균을 구해 내림차순으로 정렬했다.
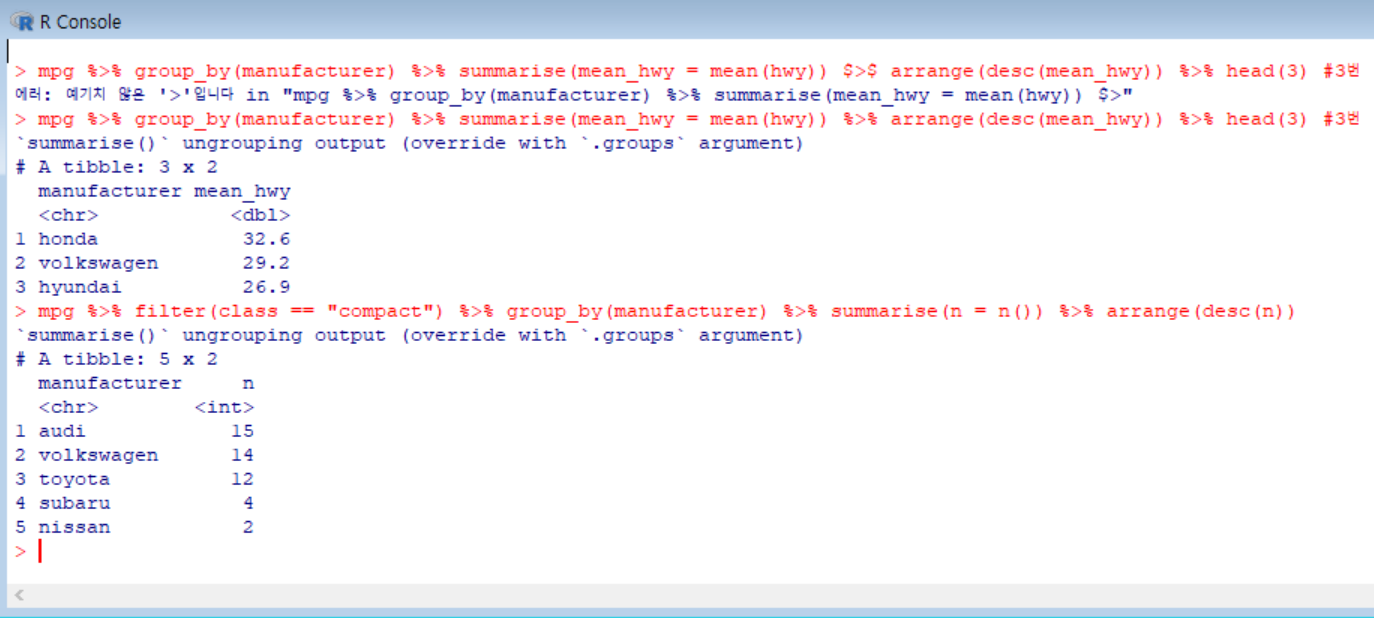
3번에서는 hwy 평균이 가장 높은 회사 세 곳을 출력해보았다. (%>% 기호를 $>$ 라고 해놔서 오류가 한번 떴다..ㅋㅋ)
4번에서는 어떤 회사에서 compact(경차) 차종을 가장 많이 생산하는지 내림차순으로 정렬해 알아보았다.
(이 문제 풀 때 조금 어려웠다. 책에 별표 쳐놨다..)
- 데이터 합치기
여러 데이터를 합쳐 하나의 데이터로 만든 후 분석할 때 유용하게 쓰인다. 데이터를 합치는 방법에는 가로로 합치는 방법, 세로로 합치는 방법이 존재한다.
가로로 합치는 경우는, 기존의 데이터에 변수(열)을 추가하는 것이다.
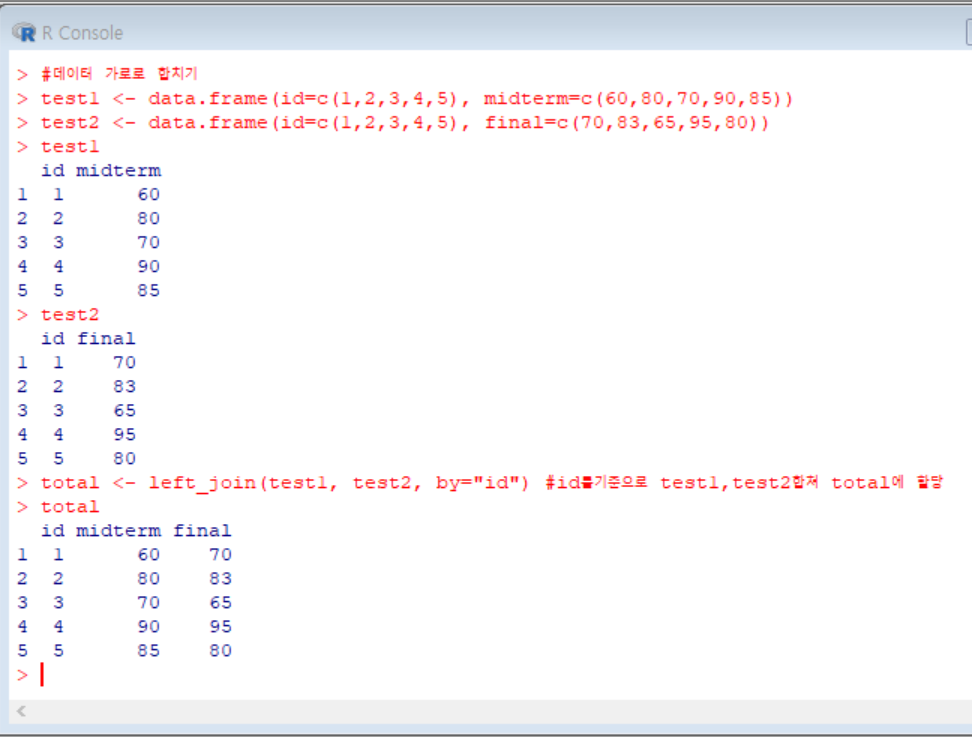
left_join(): 데이터를 가로로 합쳐준다. 가로로 데이터를 합칠 때는 기준값을 정해야 한다.
기준값은 모든 데이터에서 공통으로 가지고 있는 변수여야 한다.
위의 실습에서는 test1과 test2 모두 id라는 공통변수가 있어 기준값을 id로 설정했다.
기준값은 'by = ' 파라미터를 이용해 설정하며, 변수명 앞뒤로 따옴표(")를 붙여줘야 한다.
다음은 세로로 합치는 경우다.
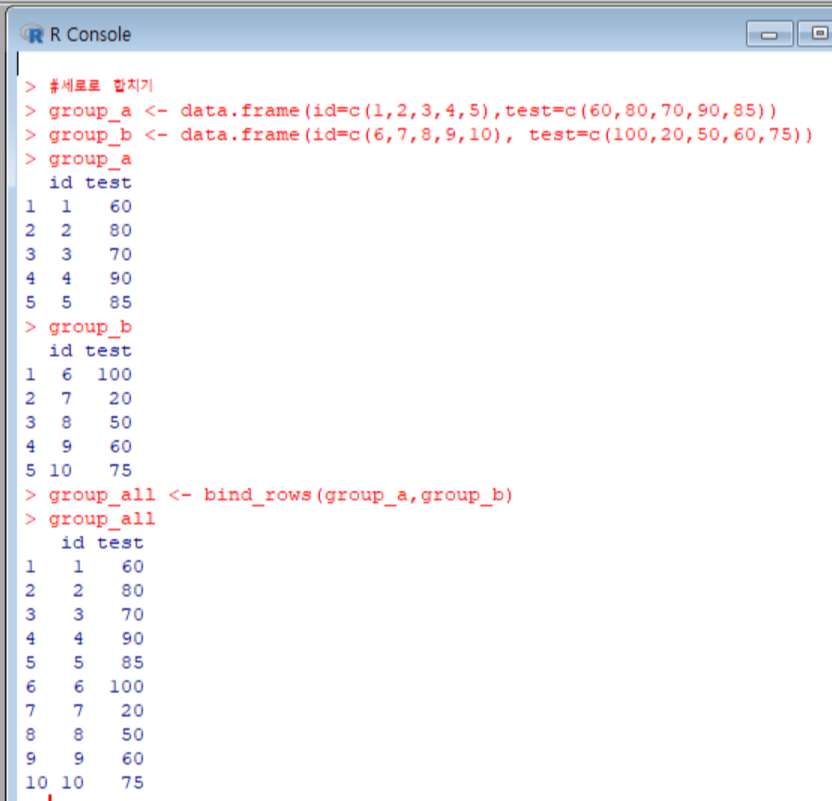
bind_rows(): 데이터를 세로로 합쳐준다.
세로로 합칠때는 두 데이터의 변수명이 같아야 한다. 위의 실습에서도 변수명이 id와 test로 동일했기 때문에 합칠 수 있었다.
만약 데이터의 변수명이 다르다면, rename()함수를 이용해 변수명을 맞춰주면 된다.
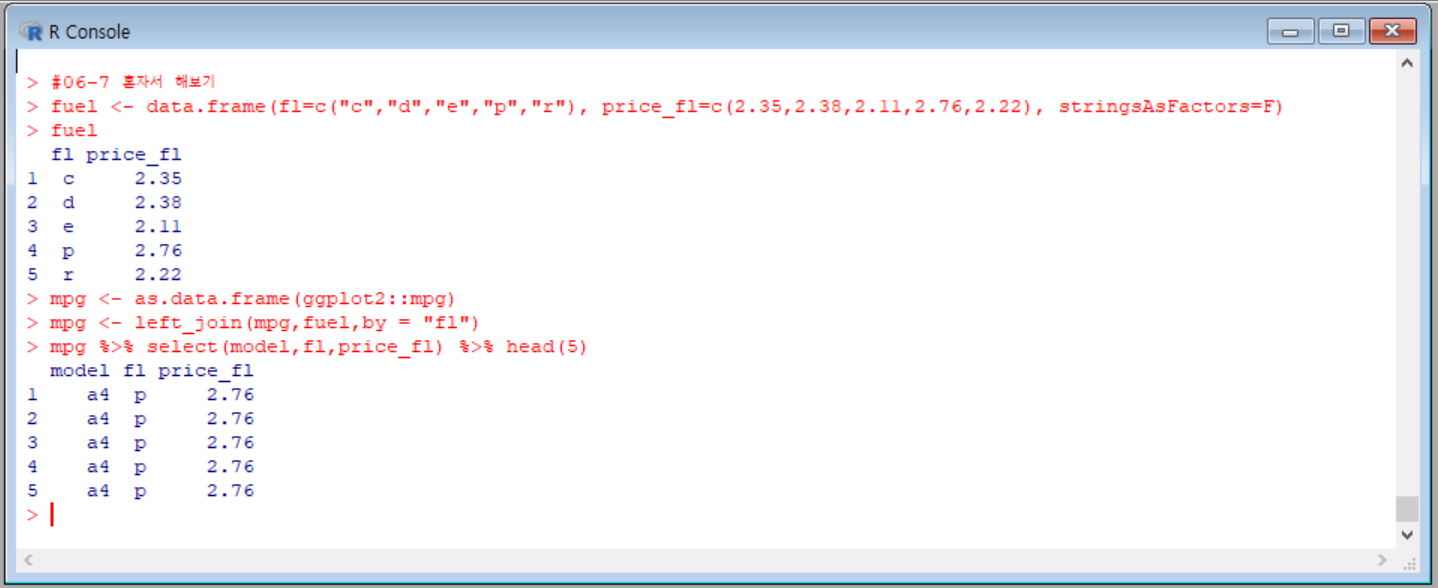
먼저, 주어진 데이터를 데이터 프레임으로 입력 시킨 후, mpg 데이터에 price_fl 변수를 합쳤다.
그리고, 잘 추가되었는지 확인하기 위해 model, fl, price_fl 변수를 앞 5행만 출력해 보았다.
성공!
- 분석 도전
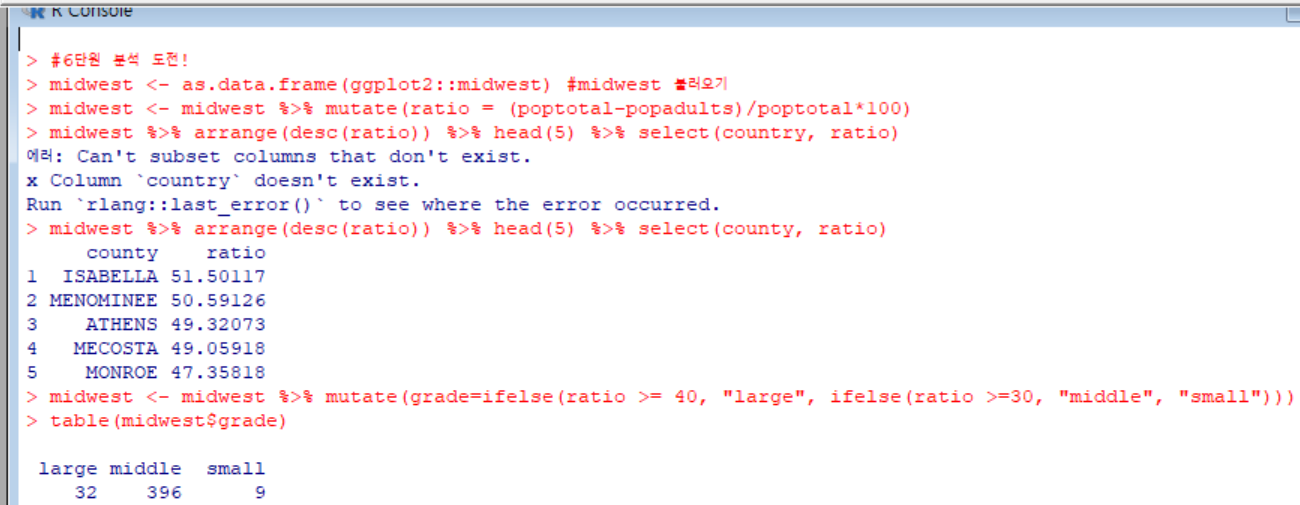
낚였어.. 변수명 country인줄 알았는데 county였음..ㅋㅋ 오류 한번 떠주고.. 문제 1,2,3번 성공!
마지막 문제 4번이 문제였어..
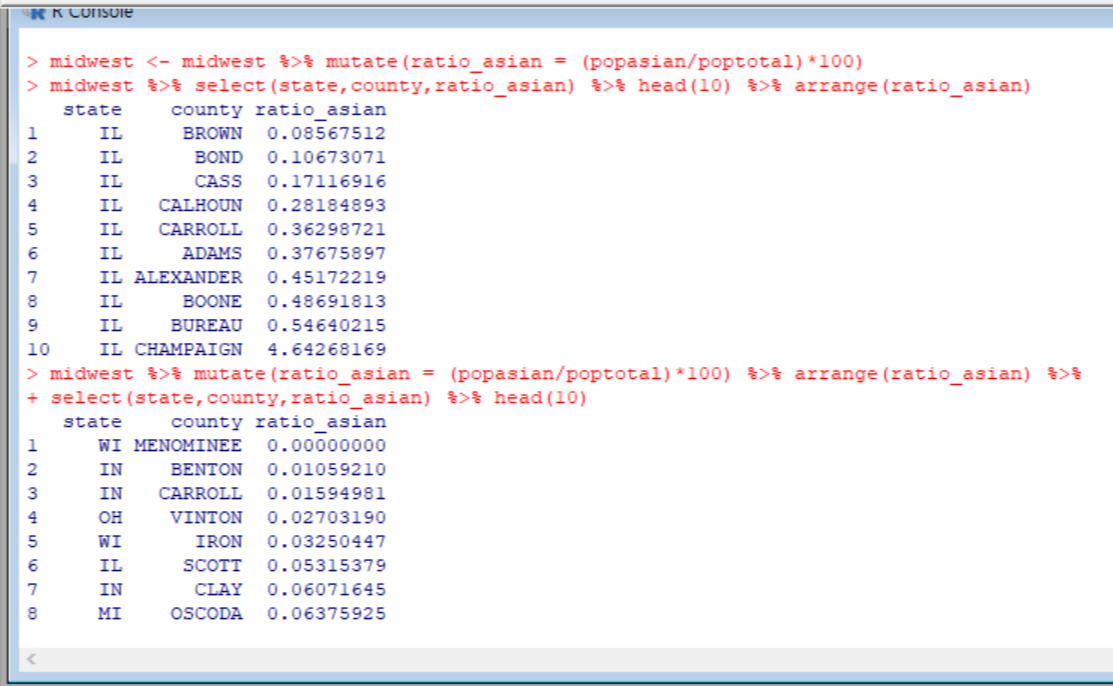
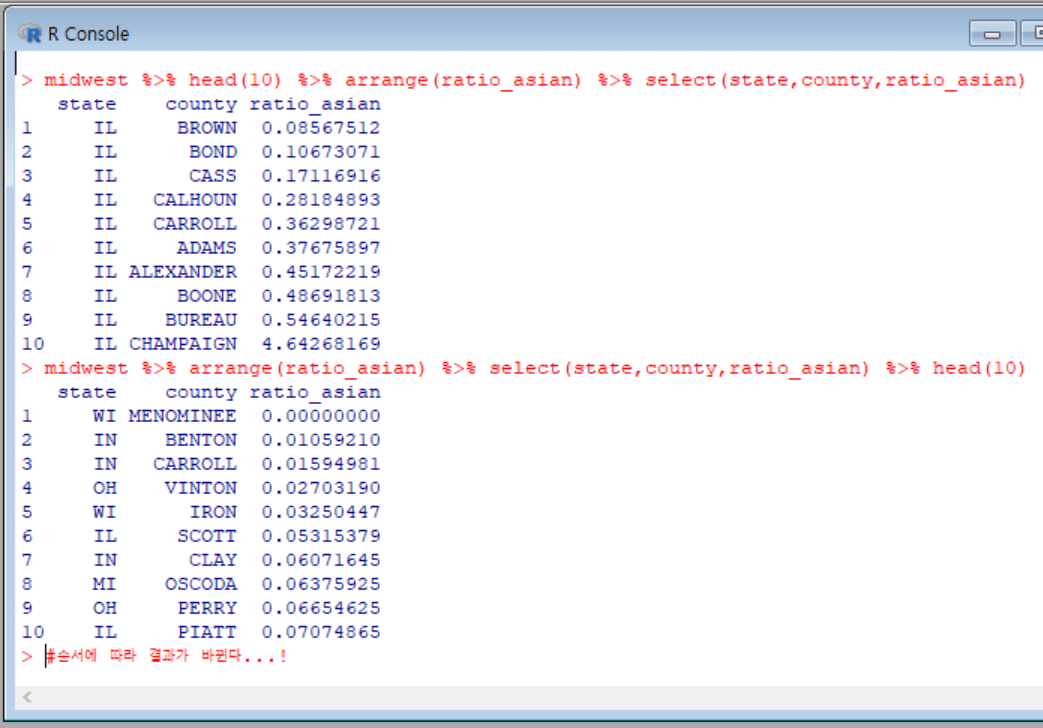
처음에 하라는대로 함수 빠짐없이 다 집어넣었고, 틀린것도 아닌거 같았는데, 답이 다르게 뜬 것이다.
그래서 풀이를 봤는데, 내가 사용했던 함수들이 다 들어있었다.
'뭐지... 설마..'하면서, 풀이대로 코드를 입력했더니 답이 다르게 떴다..!!
나는 %>% 함수가 파이프처럼 함수를 다 연결해준다고해서 함수가 나열된 순서는 상관이 없을 줄 알았는데, 함수 작성 순서에 따라 결과가 바뀌는 것이다.. 결국 문제에서 말한 순서 고대로 함수를 하나씩 입력해줘야되는 것이다..
앞에 연습문제 풀때는 생각도 못했는데.. 지금이라도 알았으니 다행이다.. 나중에 실무 들어가서 발견했으면ㅋㅋㅋㅋㅋ그동안 내가 한건 뭘까에 대한 현타가 세게 왔을듯 하다..ㅎㅠㅠ마지막 4번 문제에서 시간이 조금..많이? 들었지만 결국 오늘도 문제해결!
다음은 '데이터 정제'할 차례!
'(통계분석) R' 카테고리의 다른 글
| 09.30(수) 산점도, 막대그래프, 선그래프, 상자그림 등 그래프 만들기 (0) | 2020.09.30 |
|---|---|
| 09.28(일) 데이터 정제 (빠진 데이터, 이상한 데이터 제거하기) (0) | 2020.09.28 |
| 09.25(금) 데이터 전처리, 필요한 데이터 추출, 필요한 변수 추출 (0) | 2020.09.28 |
| 09.24(목) 데이터 파악, 변수명 변경, 파생변수 생성 (0) | 2020.09.27 |
| 09.24(목) 데이터 프레임 이해 및 생성, 외부 데이터 불러오기 (0) | 2020.09.27 |