📚해당 게시글은 '이지스 퍼블리싱' 출판, 데이터 분석가 '김영우'님이 지은 도서 "Do it! 쉽게 배우는 R 데이터 분석" 을 기반으로 작성된 게시글입니다. 저작권 문제 시 게시글을 삭제 하겠습니다 :)
- 성별 직업 빈도 (성별로 어떤 직업이 가장 많을까?)
성별과 직업 변수 모두 앞 과정에서 다루었으므로, 바로 분석으로 들어갔다.
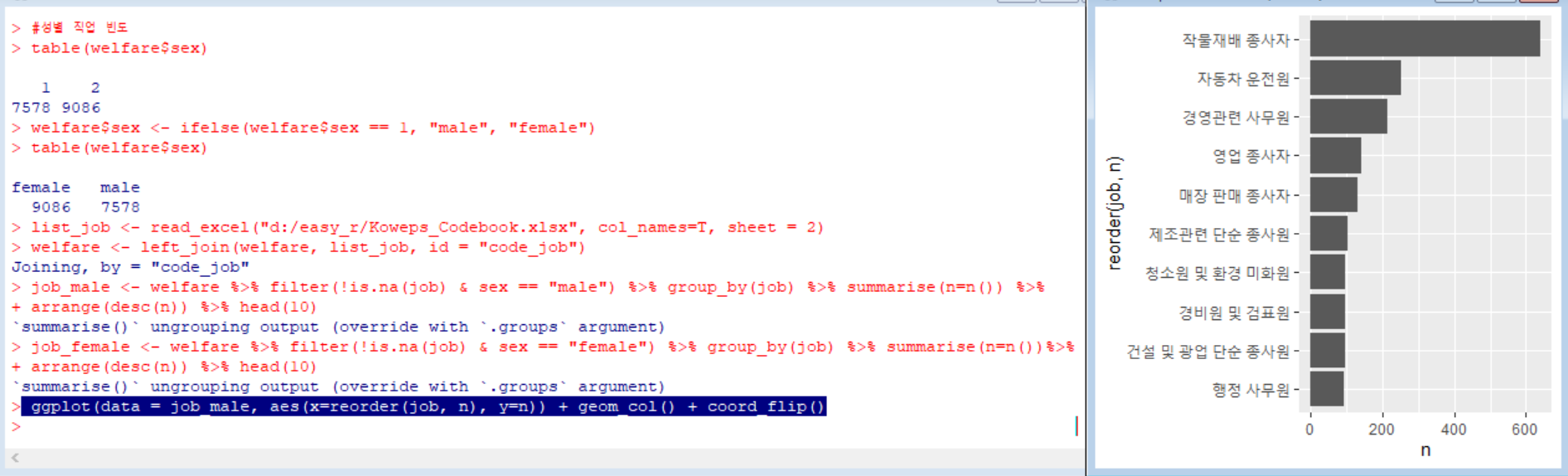
우선, 남성/여성별로 직업별 빈도를 구해 상위 10개를 추출하였다.
filter()로 성별을 지정해주고, 빈도를 구하는 것이므로 n=n()을 사용했다.
그리고, 남성 직업 빈도 상위 10개 직업 데이터를 그래프로 출력했다. 전에 배웠듯, 그래프를 90도 회전시켰고, reorder을 이용해 빈도가 많은 직업부터 순서대로 나열했다.
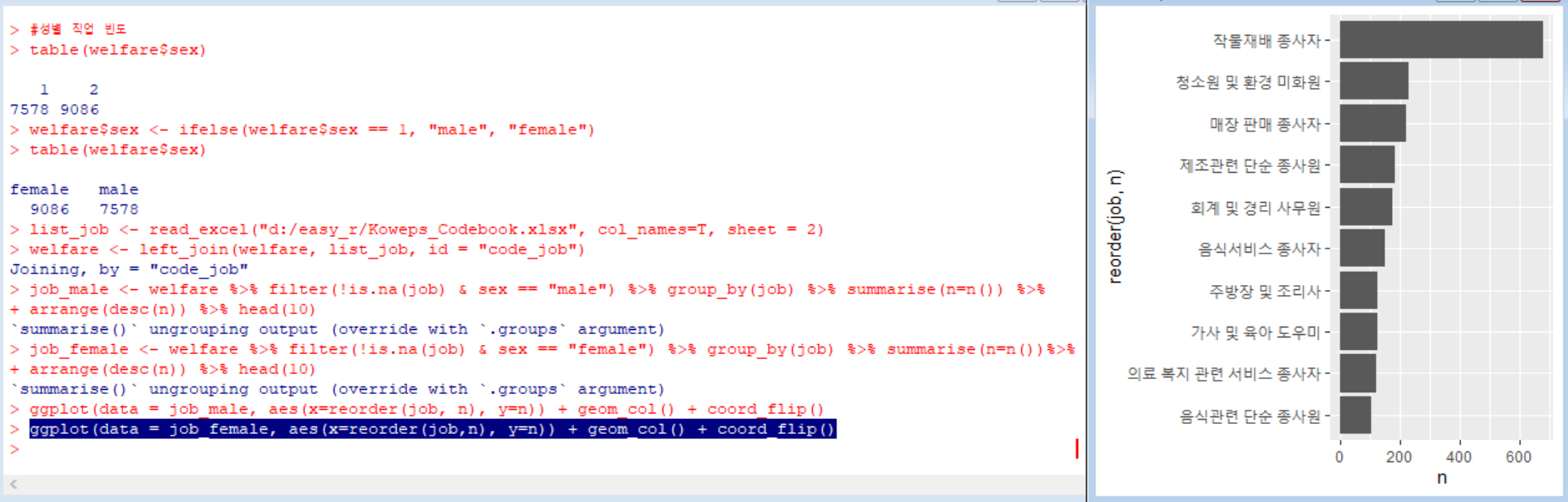
이번에는 여성 직업 빈도 상위 10개 직업 데이터를 그래프로 출력했다. 이 역시 그래프를 회전시키고, 빈도가 많은 직업부터 순서대로 나열해 보았다.
결과: 남성의 경우 가장 많이 가지고 있는 직업은 작물 재배 종사자, 자동차 운전원, 경영관련 사무원, 영업 종사자이며, 여성이 많이 가지고 있는 직업은 작물재배 종사자, 청소원 및 환경 미화원, 매장 판매 종사자, 제조관련 단순 종사원이다.
- 종교 유무에 따른 이혼율(종교가 있는 사람들이 이혼을 덜 할까?)
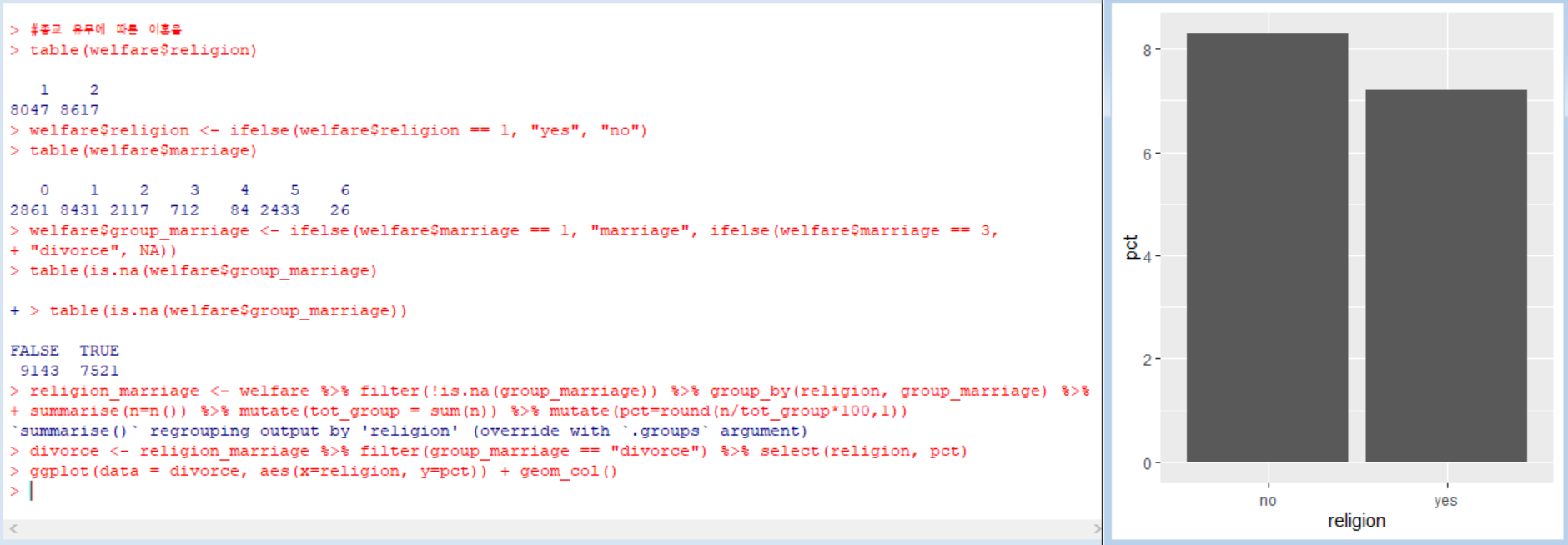
우선, religion(종교) 변수에서 1은 종교 있음, 2는 종교 없음이다.
그리고, marriage(혼인)변수는 0부터 6까지의 값을 가지고 있는데, 분석에서는 1(유배우)과 3(이혼) 값만 사용할 예정이므로 외의 값들은 결측치 처리를 한 group_marriage(혼인 상태)라는 변수를 생성했다.
분석에서, 혼인 상태의 결측치를 제외하고, 종교와 혼인상태별로 빈도 수를 출력했다. 전체 빈도의 합을 나타내는 tot_group과 혼인상태의 비율을 구한 pct 변수를 생성했다.
여기서, 소수점 한자리에서 값을 반올림하도록 round(변수, 반올림 할 자리 수)함수를 사용했다.
이제, 혼인상태에서 이혼에 해당하는 값만 추출해 이혼율 표를 만들었다. 이때는 filter()함수와 select()함수를 사용했고, 출력된 데이터를 이용해 막대 그래프를 생성했다.
결과: 종교가 있는 경우의 이혼율을 7.2%, 종교가 없는 경우의 이혼육을 8.3%로 나타남. 종교가 있는 사람들이 이혼을 덜 한다.
+ 연령대별 이혼율 분석
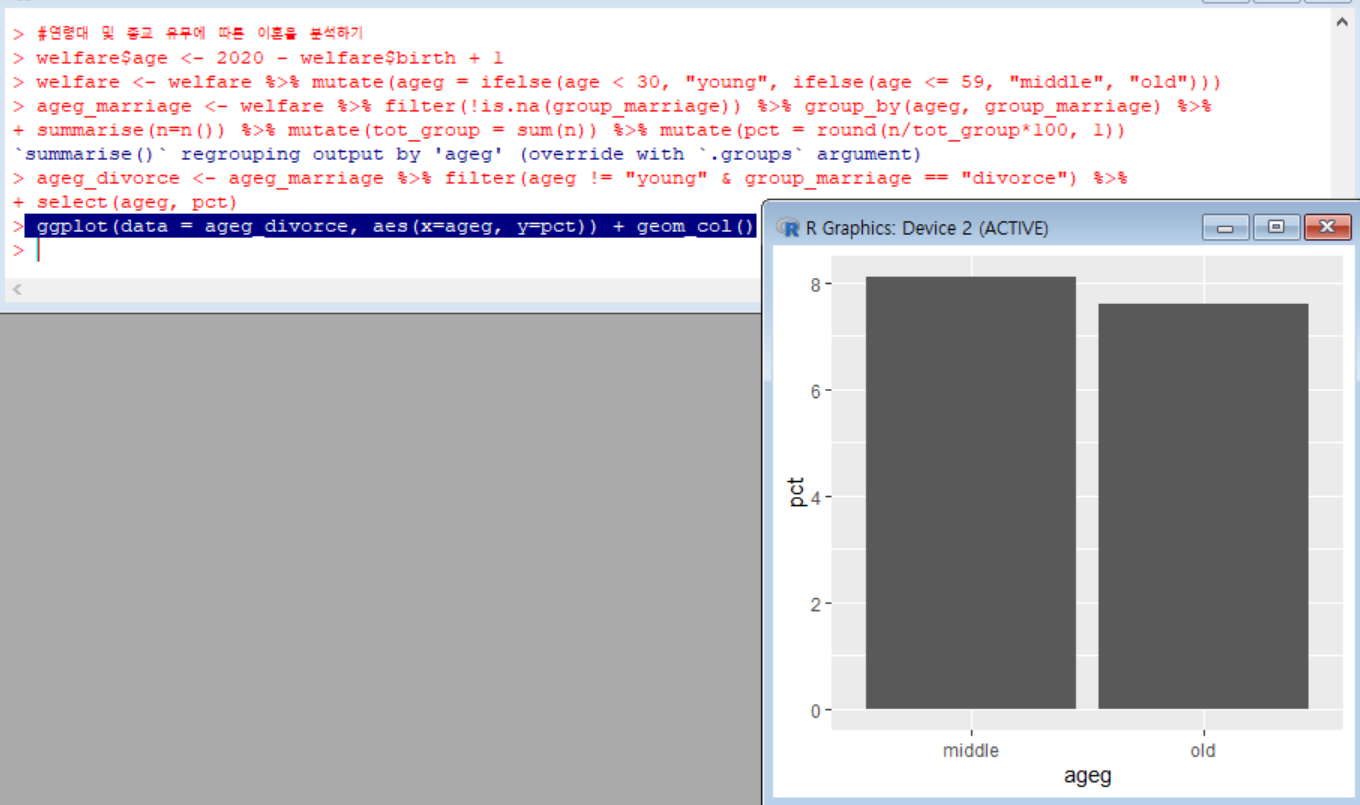
같은 방식으로, 이번에는 연령대별 이혼율을 분석해보았다.
birth 변수를 이용해 나이 변수를 만들고, 30대 미만은 초년, 30~59세는 중년, 60세 이상은 노년으로 연령대 변수를 생성했다.
그리고, 혼인상태 변수에서 결측값을 빼고, 연령대와 혼인상태 별로 나누어 빈도를 출력했다. 전체 빈도를 나타내는 tot_group 변수를 생성했고, 비율을 나타내는 pct 변수도 만들었다.
연령대가 초년인 사람들을 분석에서 제외, 혼인 상태가 이혼인 사람들만 filter()함수로 걸러내고, ageg, pct만 select 해 막대그래프를 만들었다.
결과: 중년층에서는 이혼율이 8.9%, 노년층에서는 이혼율이 6.6%이다.
+ 연령대 및 종교 유무에 따른 이혼율 표 만들기
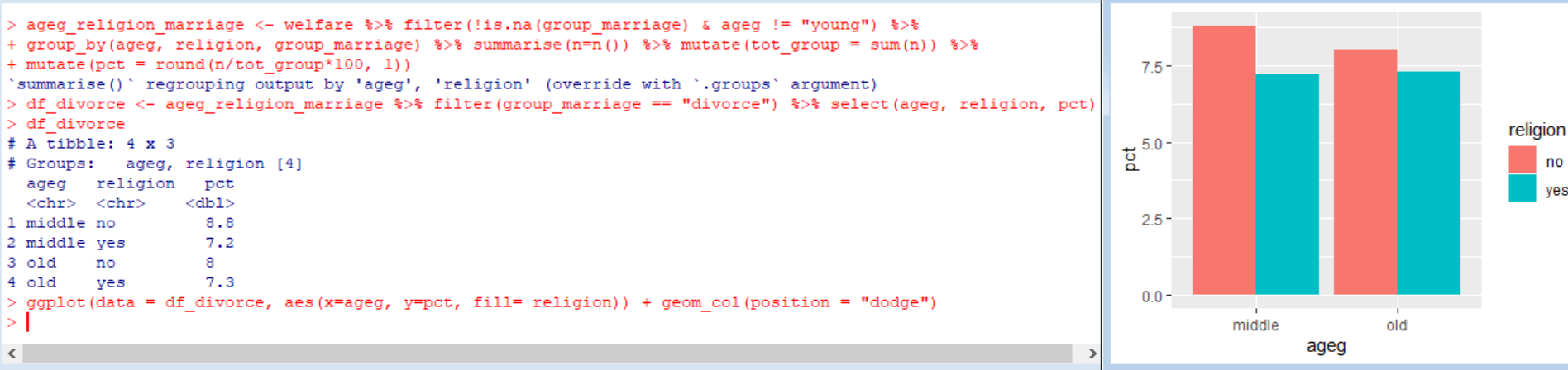
이번에는 연령대와 종교 유무 모두에 따른 이혼율을 분석해봤다.
앞의 과정들이 다 섞인 것이라고 보면 된다.. 혼인 상태의 결측치 제외하고, 연령대가 초년인 사람들을 걸러냈다.
연령대와, 종교, 혼인 상태별로 빈도를 나타냈고, 전체 빈도를 출력하는 tot_group변수와 비율을 표현하는 pct 변수도 생성했다.
그리고 여기서, 혼인 상태가 "이혼"인 사람들만 걸러내 ageg와 religion, pct 변수를 나타내도록 하는 데이터 프레임을 출력하고, 막대가 나눠지고 종교별로 색이 다른 막대그래프 또한 출력해보았다.
결과: 노년은 종교 유무에 따른 이혼율 차이가 0.1%로 작고, 오히려 종교가 있는 사람들의 이혼율이 높다.
중년은 종교가 없는 사람들의 이혼율이 1.8% 더 높다.
- 지역별 연령대 비율 (노년층이 많은 지역은 어디일까?)
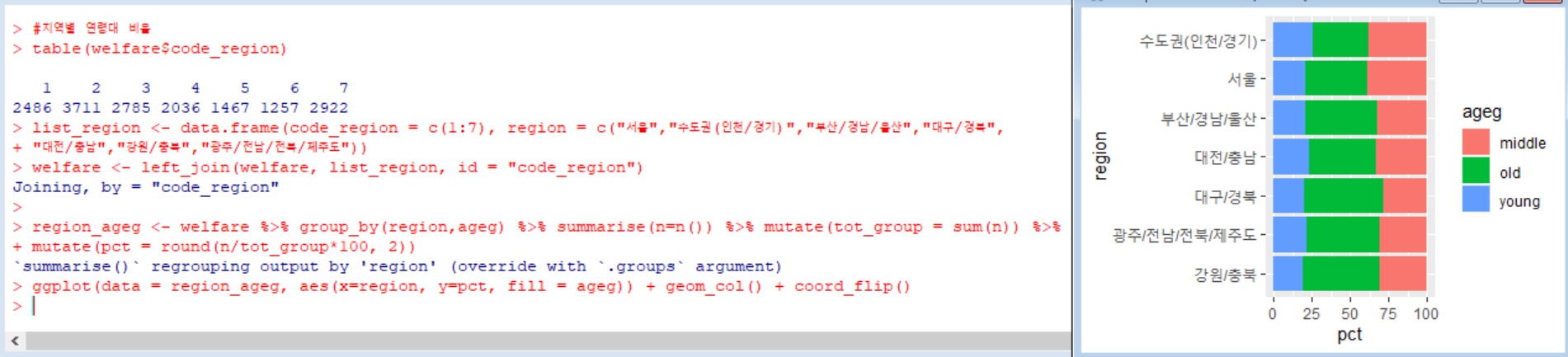
지역 변수에는 1부터 7까지의 값이 있다. 우선, 코드북을 참고해 서울, 수도권, 부산/경남/울산, 대구/경북 등 7개의 지역명 목록을 데이터프레임으로 만들었다. 그리고 1-7까지의 값을 가진 welfare 데이터에 code_region 변수를 기준으로 지역명 목록을 변수로 추가했다.
분석을 위해, welfare에서 지역과 연령대별로 빈도를 구했고, 전체 빈도의 합을 나타내는 tot_group 변수를 만들었고, round()함수를 이용해 비율이 소수점 둘째자리까지 나오는 pct 변수를 만들었다. 이를 막대그래프로 출력했는데, 연령대별로 그래프의 색이 구분되고, 그래프가 90도 회전되도록 하는 함수를 이용했다.
이렇게 그래프를 만들어보니, 연령대별로 색의 구분은 되지만 지역별 노년층 비율을 비교하는데 어려움이 있었다.
그래서, 노년층 비율이 높은 순서대로 막대를 정렬해보았다.
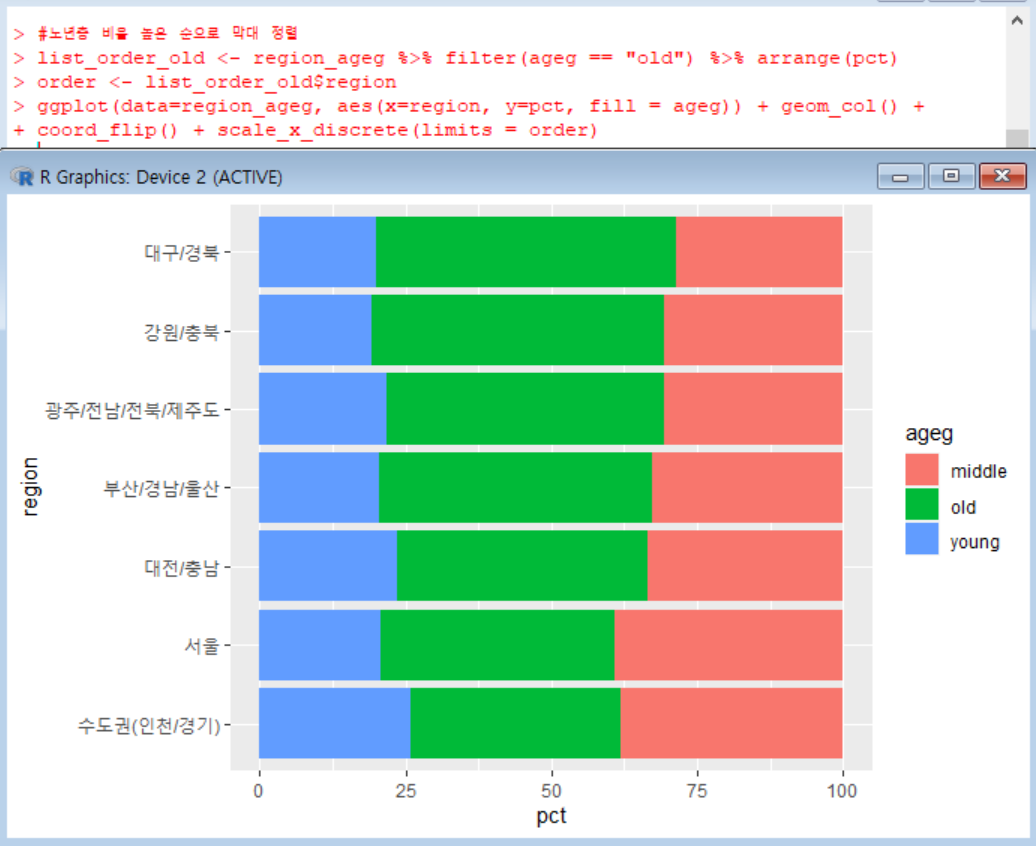
노년층 비율을 내림차순으로 정렬하는 프롬프트를 만들어 다시 그래프로 출력했다.
위에서 만든 데이터에서, filter()함수를 이용해 '노년층(old)'인 데이터만 걸러냈고, arrange()함수를 이용해 비율이 높은 순서대로 정렬되는 list_order_old라는 데이터를 만들었다.
그리고, list_order_old 데이터에서, 지역명이 노년층 비율 순서대로 정렬된 order 변수를 생성했다.
앞에서 만든 그래프 생성 코드에 scale_x_discrete()를 추가하고 limits 파라미터에 방금 생성한 order 변수를 지정하니, 막대그래프가 노년층 비율이 높은 순서대로 정렬되었다.
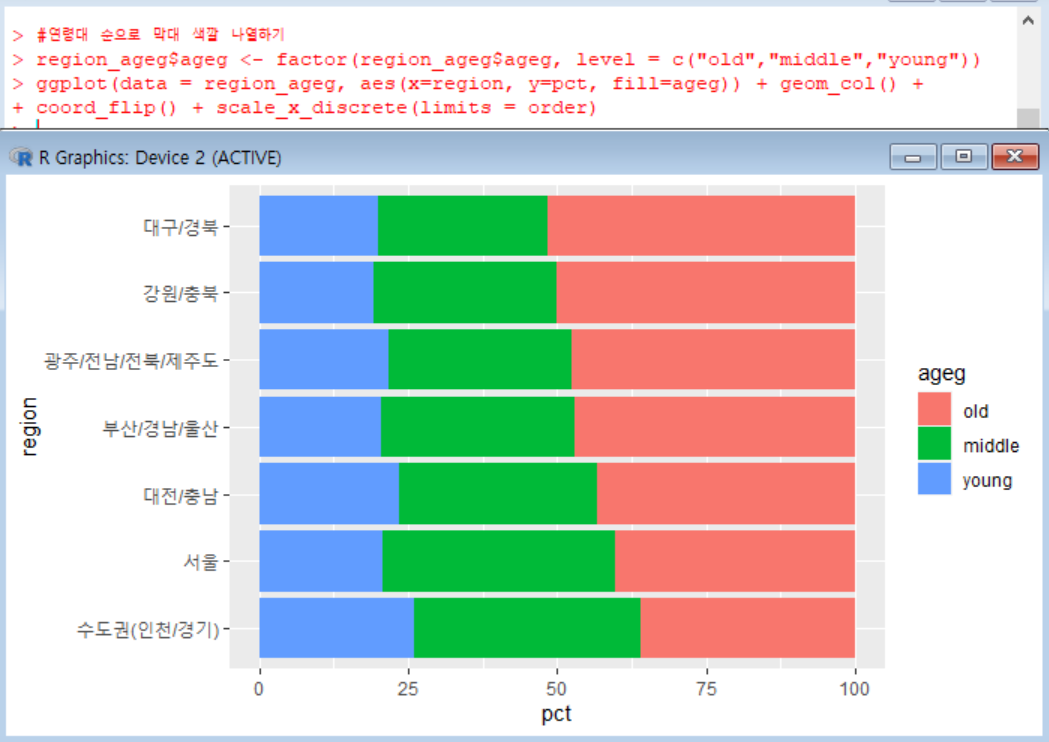
이제 마지막 단계다!
지금까지 만들었던 그래프는 막대가 초년, 노년, 중년 순으로 되어있었다.
factor() 함수를 이용해 그래프를 만드는데 계속 사용한 region_ageg 데이터의 ageg 변수를 factor 타입으로 변환하고, level 파라미터를 이용해 값의 순서를 지정했다.
그리고, 그래프 생성 코드를 다시 실행했더니, 막대의 순서가 지정한대로 바뀌어 지역별 연령대 비율의 구성을 쉽게 파악할 수 있었다.
결과: 노년층 비율은 대구/경북, 강원/충북 순으로 가장 높고, 수도권의 노년층 비율이 가장 낮았다.
이제 책에 나온 한국 복지 패널 데이터를 이용한 '한국인의 삶 파악하기'는 끝이났다. 사실 소단원 6까지는 정말 할만했는데.. 789단원이 너무 복잡하고.. 정말 어렵게 느껴졌다. 그래서 일단 닥치는대로 코딩해보고, 블로그 작성하면서 이해한 부분들이 거의... 대부분이었다..ㅠㅠ
그래도 글 작성하니까 복습이 되는 것 같아 다행이다.
코딩할 때 이해도가 10%정도였다면 지금은 60%정도 됐다....ㅠㅠ
아직은 복잡하게 느껴지니까 교재 진도 다 빼고 혼자 보건의료 데이터 분석 시작하기 전에 이 부분은 게시글이랑 교재 다시보면서 100으로 채워야지... 다짐한다...엉엉😭
'(통계분석) R' 카테고리의 다른 글
| 10.10(토) 지도의 시각화 (0) | 2020.10.11 |
|---|---|
| 10.09(금) 텍스트 마이닝 (0) | 2020.10.09 |
| 10.04(일) 데이터 분석 실전 (연령대에 따른 월급 차이, 연령대 및 성별 월급 차이, 직업별 월급 차이 분석) (0) | 2020.10.04 |
| 10.02(금) 데이터 분석 실전 (성별에 따른 월급 차이, 나이에 따른 월급 차이) (0) | 2020.10.03 |
| 09.30(수) 산점도, 막대그래프, 선그래프, 상자그림 등 그래프 만들기 (0) | 2020.09.30 |